
AIR STREaM

An anime-style illustration of Mickey Mouse inspired by “Steamboat Willie,” blending the classic black and white aesthetic with vibrant anime elements. Picture Mickey in his iconic pose, steering the boat, but with exaggerated anime features: large, expressive eyes and a more dynamic, fluid pose. The background should be a lively reinterpretation of the original steamboat setting, maintaining the vintage feel but with added depth and detail characteristic of anime. Use a monochrome palette with subtle hints of color to bridge the old and the new, creating a piece that’s both nostalgic and fresh. The overall mood is playful and energetic, capturing the essence of Mickey’s character in a new, yet familiar way. –aspect 3:2 (Niji Journey)
Samarth Reddy (3210635)
Digital Futures 2024
OCAD University
Introduction
Artificial intelligence (AI) has become a game-changer in many areas of technology, especially in digital design and modeling. My work, “AI-Enhanced Real-time Algorithm for Streamlined Rendering in a 3D Modeling Workflow (AIR STREaM)”, talks about how AI is changing the way we do 3D modeling, making it faster and more efficient. I used a method called Research through Design, which means I tried out lots of different AI platforms, models, and APIs.
At first, I divided my research into three parts: text, image, and audio-based AI platforms. For text, I looked at platforms like ChatGPT, OpenAI API, Jan AI, LM Studio, VSCode, Perplexity, and Copilot by Microsoft. For images, I used tools like Automatic 1111, Invoke, Comfy UI, Vlad Diffusion, Discord, Stability AI, Microsoft Designer, Adobe Firefly, Nvidia Omniverse, Foocus, Blockade Labs and Stable Matrix. And for audio, I tried out Eleven Labs and Natural Reader.
But as I got deeper into my research, I started to focus more on the models and user interfaces that these platforms use. In the text AI area, I looked at models like OpenAI API, GPT-3.5 and 4, Mixtral 8*7B Instruct Q4, Phi 3B Q8, GitHub Copilot, Claude 2.1, and Gemini Pro. For image models and web user interfaces, I used tools like Stable Diffusion, Midjourney, Niji Journey, Stability AI, Microsoft Designer, and Adobe Firefly.
Then, I started to think about how these AI models could be used in real-world workflows. In the text area, I tried out applications like the Obsidian note-taking app, VSCode, Cursor IDE, WebStorm IDE, Zotero, Rhino 3D and Grasshopper modeling software. For image applications, I used tools like Chainner and Grasshopper.
At the end of all this research, I did three experiments:
- I made my own GPT’s.
- I trained a custom image mode generation model using Stable Diffusion Web UI.
- I developed a near-real-time rendering engine using Grasshopper in Rhino with Stable Diffusion API integration.
These experiments showed not only how AI can be used in practice, but also how it can make our daily tasks easier by integrating it into our existing workflows. In the third experiment, I explored on how AI can improve rendering for 3D modeling workflows. This shows how AI could change the world of digital design and rendering.
Objectives
My research was guided by a few main goals, all focused on showing how AI can help in digital design:
- Exploring AI Platforms: I sorted AI platforms into types (text, image, audio) like ChatGPT and OpenAI API, and looked at how they can be used in digital design.
- Investigating AI Models/UIs: I looked at specific AI models and user interfaces, such as GPT and Stable Diffusion, to see how they can be used in design tasks.
- AI Integration in Workflows: I showed how AI can be added to daily design workflows with tools like VSCode and Grasshopper, making them more efficient and creative.
- Targeted Experiments: I did experiments to show how AI can be used in tasks like creating custom GPT models and training image models with Stable Diffusion Web UI.
- AI’s Impact on Design: I showed how AI can improve 3D modeling and rendering, especially in real-time applications.
- Evaluating AI in Workflows: I looked at the pros and cons of adding AI into existing digital design workflows.
Theme/ Topic
“AI-Driven Design Visualization”
3D Modeling | AI | Rendering
Previous work/ Context
The idea of using artificial intelligence in 3D modeling and rendering is a hot topic right now, and a lot of research is being done in this area. In this section, I’ll talk about two important pieces of work that have helped shape my own project, the AI-Enhanced Real-time Algorithm for Streamlined Rendering in a 3D Modeling Workflow (AIR STREaM).
- 3DALL-E: Using Text-to-Image AI in 3D Design Workflows
A paper by Vivian Liu, Jo Vermeulen, George Fitzmaurice, and Justin Matejka on 3DALL-E is a big step forward in using AI with computer-aided design (CAD) software. They used large language models like DALL-E, GPT-3, and CLIP to help create images in 3D design workflows. Here’s why their work is important:
- Text and Image Prompt Construction: 3DALL-E lets users make text and image prompts that use GPT-3’s huge design language knowledge to help create parts, styles, and designs. This is a big step forward in using AI to help with creative thinking in 3D modeling.
- Dynamic Interaction with CAD Viewport: The system lets designers use their current 3D progress in the CAD software as part of their image+text prompts. This makes the design process more connected and aware of the context.
- Design Process and AI Utilization Patterns: A study with 13 designers showed different ways of using AI—’AI-first’, ‘AI-last’, and ‘AI-throughout’—showing that AI can be used flexibly at different stages of the design process. This flexibility is important for the AIR STREaM project, which aims to use AI tools at various stages of the workflow.
- Inspiration Complexity and Management: Designers can explore prompts from simple to very complex (with over 10 concepts), showing that AI can handle a wide range of design challenges. Also, the idea of “prompt bibliographies” as a way to track the history of human-AI design could be very useful in understanding the AI-enhanced design process.
- Ambrosinus Toolkit in Grasshopper Github Repo with Video Demonstration
The Ambrosinus Toolkit is a great example of using AI in Grasshopper, and there’s a video that shows how it works. Here are some key points from the video and the github repo:
- Practical Use of Local AI Models: The toolkit shows how locally installed AI models can be used in Grasshopper, showing how it can be used in 3D modeling workflows.
- Potential for AI-Enhanced Rendering: Even though it’s in a raw state and uses an older version of Stable Diffusion’s control net, the toolkit shows a lot of promise for using AI in rendering processes in 3D modeling.
- Relevance to AIR STREaM Project: This real-world example gives valuable insights for the AIR STREaM project, especially in developing AI-enhanced rendering engines within design tools like Grasshopper.
- This video not only shows what the toolkit can do, but also aligns with the goals of the AIR STREaM project in using AI in 3D modeling and rendering workflows.
- Link: http://tinyurl.com/3se87dt2
Research through Design approach
My journey with the AIR STREaM project was guided by a “Research through Design” method, which means I tried out a lot of different AI tools across text, image, and audio areas, like ChatGPT, Stable Diffusion, and Natural reader. Through this method, I not only sorted and evaluated different AI platforms like OpenAI API and Adobe Firefly, but also used these tools in real design workflows. This led to the creation of custom AI applications like GPT models, image training with Stable Diffusion Web UI, and a near-real-time rendering engine, showing how AI can make 3D modeling and rendering processes more efficient and creative.
| Text | Image | Audio |
| Chat GPT | Automatic 1111 | Eleven Labs |
| Open AI API | Invoke | Natural Reader |
| Jan AI | Comfy AI | |
| LM Studio | Vlad Diffusion | |
| VsCode | Discord | |
| Perplexity | Stability AI | |
| Copilot | Microsoft Designer | |
| Adobe Firefly | ||
| Nvidia Omniverse | ||
| Fooocus | ||
| Stable Matrix |
| Models/Web UI | API | ||
| Text | Image | Text | Image |
| OpenAI API | Stable Diffusion | Obsidian | Chainner |
| Chat GPT | Mid Journey | VScode | Grasshopper |
| GPT 3.5/4 | Niji Journey | Cursor | |
| Mixtral 8*7B q4 | Stability Ai | Webstorm | |
| Phi-2 3B q8 | Microsoft Designer | Zotero | |
| Github Copilot | Adobe Firefly | Rhino/ Grasshopper | |
| Claude 2.1 | |||
| Gemini Pro | |||
| Model | Version | Type | Source | Rating |
| Anime | 1 | Anime | Hugging Face | ⭐⭐⭐⭐ |
| A.Pastel Dream | 1 | Anime | Civitai | ⭐⭐⭐ |
| Animerge | 26 | Mixed Model | Civitai | ⭐⭐⭐⭐⭐ |
| Aniverse | 16 | Mixed Model | Civitai | ⭐⭐⭐⭐⭐ |
| Architec. Exterior | 40 | Architecture | Civitai | ⭐⭐⭐ |
| Architecture RMix | 1 | Architecture | Civitai | ⭐⭐⭐ |
| Merged Protogen | 1 | Merged Model | Civitai | ⭐⭐⭐⭐ |
| Counterfeit | 30 | Anime | Civitai | ⭐⭐⭐ |
| Cyber Realistic | 41 | Realistic | Civitai | ⭐⭐⭐⭐ |
| Deliberate | 5 | Realistic | Hugging Face | ⭐⭐⭐⭐⭐ |
| Dreamshaper | 8 | Realistic | Civitai | ⭐⭐⭐⭐⭐ |
| Inkpunk | 2 | Ink | Hugging Face | ⭐⭐⭐⭐ |
| Lyriel | 13 EOL | 3D Realistic | Civitai | ⭐⭐⭐⭐ |
| Meina Pastel | 1 | Anime | Civitai | ⭐⭐⭐⭐ |
| Moon Mix Fantasy | 20 | Mixed Model | Civitai | ⭐⭐⭐⭐⭐ |
| Novel Inkpunk | 1 | Ink | Hugging Face | ⭐⭐⭐⭐ |
| Perfect Deliberate | 5 | Realistic | Civitai | ⭐⭐⭐⭐⭐ |
| Product Design | 10 | Realistic | Civitai | ⭐⭐⭐ |
| Protogen | X22 | Realistic | Civitai | ⭐⭐⭐⭐ |
| Protogen | X34 | Realistic | Civitai | ⭐⭐⭐⭐ |
| Protogen | X53 | Realistic | Civitai | ⭐⭐⭐⭐ |
| Real Cartoon 3D | 13 | 3D Cartoon | Civitai | ⭐⭐⭐⭐⭐ |
| Realistic Vision | 5 | Realistic | Civitai | ⭐⭐⭐⭐⭐ |
| Reliberate | 3 | Realistic | Hugging Face | ⭐⭐⭐⭐⭐ |
| RevAnimated | 12 EOL | Mixed Model | Civitai | ⭐⭐⭐⭐⭐ |
| Inkpunk Style | SDXL 1 | Ink | Civitai | ⭐⭐⭐ |
| Seekyou | 1 | Cartoon/ Anime | Civitai | ⭐⭐⭐⭐ |
| Synthwave Punk | 2 | Ink | Civitai | ⭐⭐⭐ |
| Toonyou | 3 | Cartoon/ Anime | Civitai | ⭐⭐⭐⭐ |
| Base Model | 1.5 | Standard | Hugging Face | ⭐⭐ |
| Midjourney | 6 | Mixed Model | Midjourney | ⭐⭐⭐⭐⭐ |
| Niji Journey | 5 | Anime/ Cartoon | Niji Journey | ⭐⭐⭐⭐⭐ |
| MS Designer | – | Mixed Model | MS Designer | ⭐⭐⭐⭐ |

I used Stable Diffusion, especially the WebUI (Automatic 1111) version, to create the images (numbered 0 to 30) mentioned above. The configuration details for the creation process are as follows: The standard configuration is kept the same across all generations of different models, with the changes limited to the seed and the model used. For Midjourney and Niji Journey, only positive prompts are used. Also, the prompt for Microsoft Designer is different because of an unexpected copyright error. Along with the main checkpoint/safety tensor model, the above images are the result of two LoRAs: Mickey Mouse and M1cky5. Both LoRAs were given weights of 0.4 and 0.7, respectively, for the best results.
Stable Diffusion:
Positive Prompt:
(((stylized))), vivid ((upper body)) closeup portrait of ((Mickey Mouse)) in a horror style in an epic horror environment with a Focus on capturing the iconic features: large ears, bright button eyes, and a creepy smile. The image should be high-resolution and ultra-detailed, showcasing Mickey’s classic red shorts and white gloves. Use a clear, plain background to emphasize Mickey’s vibrant character. The overall mood is grunge and creepy, reminiscent of disney, with a focus on sharp, clean lines and a bright color palette.
LoRA: <lora:mickey mouse:0.4> <lora:M1cky5(0.7-1)CIVIT:0.4>
Negative Prompt: CS-OBG ng_deepnegative_v1_75t Unspeakable-Horrors-Composition-4v, Watermark, Text, censored, deformed, bad anatomy, disfigured, poorly drawn face, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, disconnected head, malformed hands, long neck, mutated hands and fingers, bad hands, missing fingers, cropped, worst quality, low quality, mutation, poorly drawn, huge calf, bad hands, fused hand, missing hand, disappearing arms, disappearing thigh, disappearing calf, disappearing legs, missing fingers, fused fingers, abnormal eye proportion, Abnormal hands, abnormal legs, abnormal feet, abnormal fingers
Steps: 20 Sampler: DDIM CFG scale: 7
Seed: -1
Size: 600×600 Model: -1
Denoising strength: 0.5
Hires upscale: 2
Hires upscaler: Latent
—-
Microsoft Designer
Prompt: Stylized and vivid closeup portrait of Mickey Mouse in epic horror style
Experiments
I carried out a few experiments to show how AI can be used in practice. These experiments covered a range of areas, from creating custom GPT models to advanced AI model training and integration into design tools.
Experiment 1: Text-based AI Experiments for Custom GPTs
In this experiment, I focused on creating custom GPT models for different uses:
Ava: This is a GPT model that’s all about UX research. It’s great at understanding and explaining complex UX papers and ideas. I didn’t upload any specific training data for this one.
Taco: This model is a guide for ethical human research. It interprets and applies TCPS 2 guidelines and gives precise advice. I used general public available data as custom instruction for this one.
Vada: This model is made for international students. It provides Indian recipes and cultural insights. I didn’t upload any specific training data for this one.
Maple: This is a guide for Canadian English. It specializes in cultural nuances, idioms, and regional language variations. I didn’t upload any specific training data for this one.
Poet: This model is designed to generate imaginative prompts for AI-generated images, specifically tailored for Mid Journey. I created custom instructions for training this one.
Experiment 2: Custom Safe Tensor Model Training
In this experiment, I trained a custom Safe tensor model using Khoya GUI to understand the alien language logograms from the movie “Arrival.” Even though the training was successful, the model had a hard time with the complexities of language translation. This shows the challenges in creating AI models that need to interpret and infer language deeply. Links:GitHub – WolframResearch/Arrival-Movie-Live-Coding: Documents from a live coding session by Christopher Wolfram related to content from the 2016 film Arrival

Images used for training
Experiment 3: Making Visuals More Realistic in 3D Modeling
In this experiment, I used the Ambrosinus Toolkit in Rhino Grasshopper and neural networks like Control Net version 1 to generate image-to-image. I turned the Rhino viewport into realistic or stylized visuals based on positive and negative prompts. This shows a new way of using AI in 3D design visualization. I’ll talk more about this experiment in the next sections.
Workflows
Exploration in Stable Diffusion:
When I was playing around with Stable Diffusion, I was really interested in how it could generate images from other reference images. I tried this out by taking a screenshot of a simple 3D model from Rhino’s viewport and using it in Automatic 1111 to make a new image. The process was cool, but it didn’t give me much control over what the new images looked like. Most of the time, the results were hit or miss, and only sometimes did I get an image that looked good. This showed me that we need a better way to use AI in design that we can control more. So, I started using the Control Net extension with Stable Diffusion, which was a big improvement. I also looked into using depth maps, canny, and pose models.
Traditional Design and Animation Workflows:
The usual way of doing design and animation takes a lot of steps and time. You have to model in 3D, create meshes, add textures, unwrap, bake, set up lighting, etc. All these steps and more take a lot of work and slow down how quickly I can see and change my designs in 3D spaces like Rhino. It’s hard to get quick feedback on my 3D models because it takes so long to see the final look.
Proposed AI-Assisted Workflows:
To make the workflow seamless, I came up with a new pipeline that uses AI to help see designs better while I’m modeling in 3D. This new way uses Stable Diffusion and Control Net and fits right into the design process:
- I do the 3D modeling on one screen or viewport.
- Then, in the Grasshopper interface, I type in what I want to see and what I don’t (positive and negative prompts) and start the process with just a click.
- Right away, I can see the AI’s take on my 3D model in the Grasshopper space, which lets me quickly try out different looks.
This AI-assisted method speeds up the whole design process and gives me a quick way to see changes, which really helps me be more creative and efficient when I’m working on 3D modeling and coming up with new designs.
Experiment 3 – AI-Enhanced Real-time Algorithm for Streamlined Rendering in a 3D Modeling workflow (AIR STREaM)
This experiment is all about using extension models like Control Net version 1 of stable diffusion in the Rhino and Grasshopper workflow through a Local API for image-to-image generation. The main goal is to change Rhino’s 3D viewport model view into realistic or stylized visuals based on certain prompts and parameters.
Here’s how it works: I take a screenshot from Rhino’s viewport that shows a 3D model I’ve made. This screenshot is then used as the input image for the Control Net neural network within the Grasshopper environment. Here, I give relevant prompts, both positive and negative, along with parameters.
Once I’ve finalized the prompts and tuned the parameters, I start the AI-based image generation with a single click within Grasshopper. This makes Control Net change the Rhino viewport screenshot into a realistic or stylized image, as specified by the prompts. Below is the full algorithm description with screenshots.
Step 1:
This algorithm is the first step in connecting a local installation of Stable Diffusion (Automatic 1111) through its API. Users can choose a startup configuration that fits their hardware capabilities and usage scenarios. To start, it’s important to specify the directory of Stable Diffusion using a path file component. After linking all the necessary components and finishing the setup, the next step is to set up the WebUI. Once this is done, starting the program is as simple as pressing the “start” button. When it starts, Stable Diffusion begins operation, which you can see on the terminal/ CLI loading screen. The components used in this Grasshopper algorithm include both native Grasshopper elements and several using the Abrosinus Tool kit.
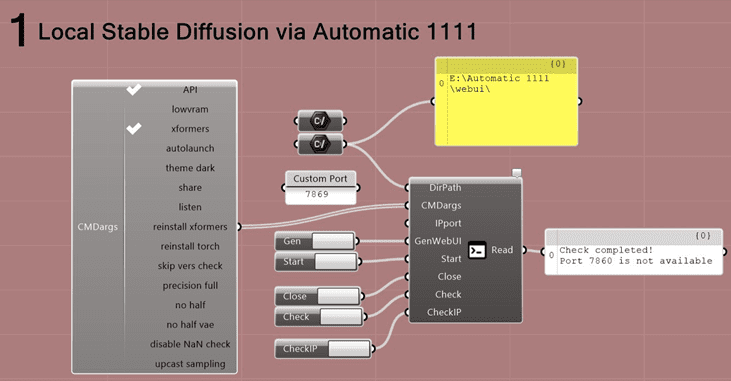
Initiation of Stable Diffusion using LoadSD Local component
Step 2:
After getting Stable Diffusion started through the API, the next thing I do is pick the model I want to use for making the image. The model I choose here will decide if the image looks realistic or more like a style. I have to pick the right model based on what kind of look I’m going for. In this part of the Grasshopper algorithm, I use a mix of the usual Grasshopper parts and some parts from the Abrosinus Toolkit.
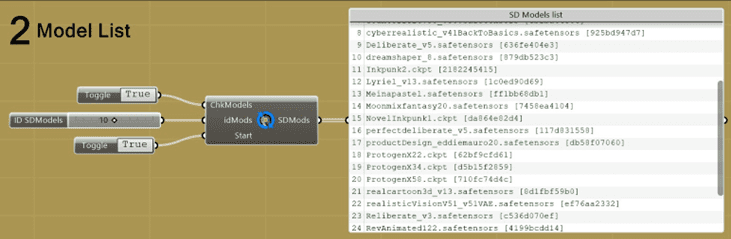
Loading Local Models for selection
Step 3:
With the model picked out, I then start modeling in 3D in Rhino. This is just the normal way I work, where the viewport I’m using for modeling is where I get the image from. I take a screenshot of this viewport with the Grasshopper algorithm, and this screenshot is what I’ll use in the Stable Diffusion process to make a new image.
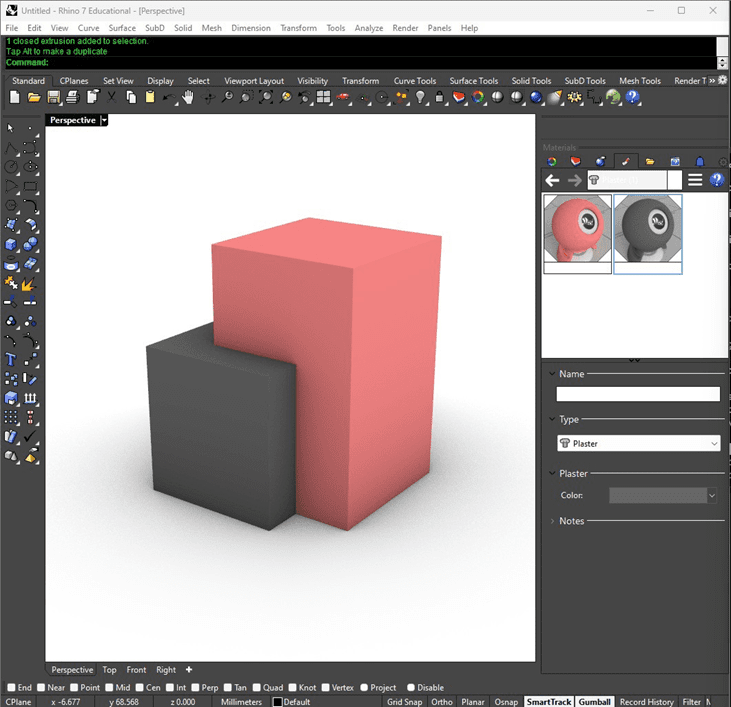
Rhino 3D viewport for 3D modeling
Step 4:
While I’m working on the 3D model, I move on to step 4, where the main part of the algorithm does its job. This part is all about making a new image from an image. It’s important to know that every time I change something in the algorithm, Stable Diffusion makes a new image. Depending on how fast my computer is, it might seem like Grasshopper has stopped working.Here’s what the algorithm includes:
- A way to choose the Control Net Version
- A model selector for Control Net (like Depth, Canny, Open pose, Scribble, etc.)
- Space to write the positive and negative prompts
- A place to put the directory path for the input images
- Settings for steps, CFG scale, weight, and guidance scale
- Options for the image width and height
- Choices for the sampler method (like DDIM, Eular a, Karras, etc.)
- A spot for the seed
Stable Diffusion is different from Midjourney, even though they both make images with AI. With Stable Diffusion, I have more control and can really shape the outcome. When I’m writing prompts for Stable Diffusion, especially with LoRA models, I have to be pretty specific to make sure the prompts work right. This need to write prompts in a certain way is what makes Stable Diffusion unique in how it makes images compared to Midjourney.
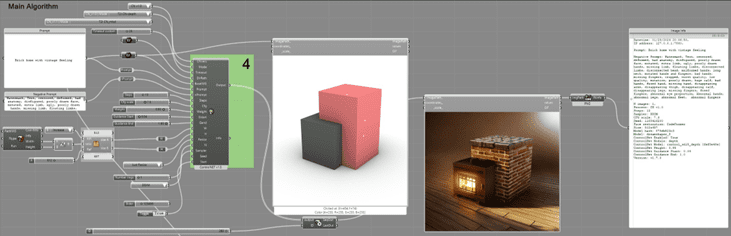
Main Algorithm for Image to Image generation (Prompt input and Control net)
The “Generated Image Info” part of the algorithm keeps all the details about an image. It saves this info and also shows it in the Grasshopper interface, which makes it easy to see and understand all the details about the images I make.
Here’s an example of how I set it up:
Prompt: Brick home with vintage feeling
Negative Prompt: Watermark, Text, censored, deformed, bad anatomy, disfigured, poorly drawn face, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, disconnected head, malformed hands, long neck, mutated hands and fingers, bad hands, missing fingers, cropped, worst quality, low quality, mutation, poorly drawn, bad hands, fused hand, missing hand, disappearing arms, disappearing legs, missing fingers, fused fingers, abnormal eye proportion, Abnormal hands, abnormal legs, abnormal feet, abnormal fingers (Standard Negative Prompt)
N images: 1,
Process: CN v1.0
Steps: 13
Sampler: DDIM
CFG scale: 7.3
Seed: 1168416200
Face restoration: CodeFormer
Size: 512×457
Model hash: 879db523c3
Model: dreamshaper_8
ControlNet Enabled: True
ControlNet Module: depth
ControlNet Model: control_sd15_depth [fef5e48e]
ControlNet Weight: 0.93
ControlNet Guidance Start: 0.04
ControlNet Guidance End: 1.0
Version: v1.7.0
Step 5:
The last step is pretty simple. I just set up a way to take screenshots of the Rhino 3D modeling interface. These screenshots go into the Step 4 algorithm to start making a new image. This step is like the control panel; it decides which view gets captured and sent to the main algorithm for making the image. It also has a part that saves all the screenshots in a certain folder, so I can keep track of all the images I’ve used in the process.
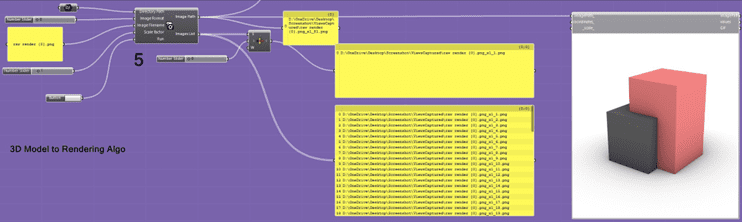
Image/ Screenshot capture algorithm
Below are some samples of the 3D model to Render workflow:

Prompt: Create an image of a Voxel Man standing, set against a simple, empty background to emphasize his form. This character, constructed from brightly colored 3D voxel cubes, radiates a pixelated, retro video game charm. He stands upright, showcasing a straightforward pose that highlights his blocky structure and the clean lines of his voxel-based design. The empty background is a solid color, perhaps a soft neutral or pastel shade, to ensure the Voxel Man is the central focus. The lighting is straightforward and evenly distributed, casting subtle shadows that define his cubic form without overwhelming the simplicity of the scene. The mood is playful yet minimalistic, capturing the essence of voxel art with a modern, clean aesthetic. The overall composition is crisp and focused, with an emphasis on the geometric beauty and vibrant colors of the voxel cubes.
Negative Prompt: Watermark, Text, censored, deformed, bad anatomy, disfigured, poorly drawn face, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, disconnected head, malformed hands, long neck, mutated hands and fingers, bad hands, missing fingers, cropped, worst quality, low quality, mutation, poorly drawn, huge calf, bad hands, fused hand, missing hand, disappearing arms, disappearing thigh, disappearing calf, disappearing legs, missing fingers, fused fingers, abnormal eye proportion, Abnormal hands, abnormal legs, abnormal feet, abnormal fingers
N images: 1,
Process: CN vl .0
Steps: 13
Sampler: DDIM
CFG scale: 7.3
Seed:3902787
Face restoration: CodeFormer
Size: 1000xl 098
Model hash: 980cb713af
Model: reliberate_vl0
ControlNet Enabled: True
ControlNet Module: depth
ControlNet Model: control_sd1S_depth [fef5e48e]
ControlNet Weight: 0.93
ControlNet Guidance Start: 0.04
ControlNet Guidance End: 1.0
Version: vl .7.0

Prompt: In a landscape of red Martian soil and jagged rocks, envision a Brutalist-style habitat, characterized by its stark, monolithic appearance. The habitat, massive and geometric, is composed of rugged, unadorned concrete with sharp lines and an imposing, fortress-like demeanor. The structure dominates the barren Martian terrain, with large, angular windows that are few and strategically placed, allowing a glimpse of the harsh, yet mesmerizing Martian environment outside. The habitat?s exterior is weathered, showcasing the effects of Martian dust storms, while the interior glimpses reveal a contrastingly warm and lively human presence. The habitat stands under a deep, rust-colored sky, casting long, dramatic shadows in the low sunlight, embodying a sense of isolation and resilience. The image conveys a mood of austere beauty and the stark reality of extraterrestrial survival, perfectly suited for a highly detailed, realistic rendering.
Negative Prompt: Watermark, Text, censored, deformed, bad anatomy, disfigured, poorly drawn face, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, disconnected head, malformed hands, long neck, mutated hands and fingers, bad hands, missing fingers, cropped, worst quality, low quality, mutation, poorly drawn, huge calf, bad hands, fused hand, missing hand, disappearing arms, disappearing thigh, disappearing calf, disappearing legs, missing fingers, fused fingers, abnormal eye proportion, Abnormal hands, abnormal legs, abnormal feet, abnormal fingers
N images: 1,
Process: CN vl .0
Steps: 13
Sampler: DDIM
CFG scale: 7.3
Seed:1279902862
Face restoration: CodeFormer
Size: 1000xl 098
Model hash: ef76aa2332
Model: realisticVisionVS1_vS1VAE
ControlNet Enabled: True
ControlNet Module: depth
ControlNet Model: control_sd1S_depth [fef5e48e]
ControlNet Weight: 0.95
ControlNet Guidance Start: 0.04
ControlNet Guidance End: 1.0 Version: vl .7.0

Prompt: Milk Bottle, masterpiece, HD, unreal engine, 4K, Minimal,Product Design, Innovative Stickers, Futuristic Design
Negative Prompt: Watermark, Text, censored, deformed, bad anatomy, disfigured, poorly drawn face, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, disconnected head, malformed hands, long neck, mutated hands and fingers, bad hands, missing fingers, cropped, worst quality, low quality, mutation, poorly drawn, huge calf, bad hands, fused hand, missing hand, disappearing arms, disappearing thigh, disappearing calf, disappearing legs, missing fingers, fused fingers, abnormal eye proportion, Abnormal hands, abnormal legs, abnormal feet, abnormal fingers
N images: 1,
Process: CN vl .0
Steps: 13
Sampler: DDIM
CFG scale: 7.3
Seed:2004396693
Face restoration: CodeFormer
Size: 512×562
Model hash: 770d3d3185
Model: animerge_v26
ControlNet Enabled: True
ControlNet Module: depth
ControlNet Model: control_sd1S_depth [fef5e48e]
ControlNet Weight: 0.85
ControlNet Guidance Start: 0.04
ControlNet Guidance End: 1.0
Version: vl .7.0

Prompt: Create an image of an exquisitely crafted perfume bottle, shimmering with the clarity of fine glass. This bottle, unique in its design, features sharp, star-like edges that catch and refract light, casting a spectrum of dazzling colors. Imagine it set against a softly blurred, monochromatic background that accentuates its clear, angular form. The bottle should be central in the composition, with a focus on its geometric precision and the way its surfaces create a dance of light and shadow. The lighting should be soft yet directional, highlighting the sharp edges and the graceful curves of the bottle, evoking a sense of luxury and elegance. The overall mood is one of sophisticated serenity, where the bottle’s delicate beauty stands out in a harmonious balance of light and form.
Negative Prompt: Watermark, Text, censored, deformed, bad anatomy, disfigured, poorly drawn face, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, disconnected head, malformed hands, long neck, mutated hands and fingers, bad hands, missing fingers, cropped, worst quality, low quality, mutation, poorly drawn, huge calf, bad hands, fused hand, missing hand, disappearing arms, disappearing thigh, disappearing calf, disappearing legs, missing fingers, fused fingers, abnormal eye proportion, Abnormal hands, abnormal legs, abnormal feet, abnormal fingers
N images: 1,
Process: CN vl .0
Steps: 13
Sampler: DDIM
CFG scale: 7.3
Seed:2008545859
Face restoration: CodeFormer
Size: 512×511
Model hash: 925bd947d7
Model: cyberrealistic_v41BackToBasics
ControlNet Enabled: True
ControlNet Module: depth
ControlNet Model: control_sd1S_depth [fef5e48e]
ControlNet Weight: 1.0
ControlNet Guidance Start: 0.04
ControlNet Guidance End: 1.0
Version: vl .7.0
Tools and Technologies
For my research on making 3D modeling workflows faster with AI, I used a bunch of different tools and technologies.
Hardware
I needed some pretty powerful hardware to handle the AI image generation with Stable Diffusion and the 3D modeling and design in Rhino3D/Grasshopper:
- RAM: I used 32 GB of RAM so I could run different processes at the same time.
- GPU: I had an Nvidia RTX 3080 with 10GB, which is good for making the AI models work faster.
- Storage: I used a 500GB disc space to keep all the model assets and the images I created.
Software
Here are the main software tools and platforms I used:
- Automatic 1111: This is the Stable Diffusion Web UI that I used to make images.
- Python 3.10.6: Used for autmatic 1111.
- Git: version control and download the recent changes made in Automatic 1111.
- Model Files: I got AI model files from places like HuggingFace and Civitai.
- CUDA Toolkit: This is for making the GPU work better.
- Rhinoceros 7: This is the 3D modeling software I used.
- Grasshopper: It’s a tool for visual scripting in Rhino.
- Ambrosinus Toolkit: This helped me integrate AI in Grasshopper.
- Lady Bug: I used this for previwing images on the canvas.
- Moonlight: Dark mode extension.
- Bifocals: I used this to see what components are on screen.
- Discord: I used this for Midjourney and Niji Journey generations.
Reflections on the Outcome
Working on this project, which utilized a Research through Design approach, was particularly engaging, especially given the involvement of cutting-edge technologies. While I relished the opportunity to delve into various AI tools spanning text, image, and audio domains, including ChatGPT, Stable Diffusion, and Natural reader, I do wish there had been more time to explore augmented reality (AR) projects.
This endeavor involved a comprehensive exploration of different AI platforms such as OpenAI, Adobe Firefly, Midjourney, and Stable Diffusion. More than just an assessment, it integrated these tools into practical design workflows. This integration led to the creation of custom AI applications, including tailored GPT models, image training with Stable Diffusion’s Web UI, and the development of a near-real-time rendering engine. Such advancements underscore the transformative potential of AI in boosting efficiency and creativity within the realms of 3D modeling and rendering.
This journey provided invaluable insights into AI’s capabilities in augmenting design workflows but also highlighted the challenges in seamlessly incorporating such rapidly evolving tools. Key takeaways include:
- The versatility of AI is immense, and its potential to enhance design workflows is significant. However, selecting the right tools through meticulous testing is crucial for success.
- Effective integration of AI technologies requires thoughtful user experience (UX) design and appropriate hardware provisions to ensure that existing workflows are not disrupted.
- Customizing prompts and model development is critical to ensure AI outcomes align with ethical standards and to prevent the propagation of bias.
- Realizing the full capabilities of AI hinges on careful tool selection, UX considerations, technical infrastructure, and skilled prompt engineering.
- The requirement for substantial computational resources presents a notable challenge.
- The installation process and ensuring error-free functioning demand considerable effort and expertise.
- API integrations, while powerful, can be complex and often lack sufficient guidance.
- Testing a multitude of models is a time-intensive endeavor.
Evaluation
To assess the efficacy of the AI integration experiments conducted in enhancing real-time rendering for 3D modeling, the following criteria were evaluated:
| Sl | Criteria | Description | Yes/ Needs Improvement | Justification |
| 1 | Learnability/ Ease of use. | Easy to learn and use. | Needs Improvement | The integration of stable diffusion with Rhino, Grasshopper requires a steep learning curve. Better tutorials and onboarding processes are needed. |
| 2 | Efficiency. | Workflow improvement. | Yes | The integration speeds up design workflows by enabling quick iterative visualization. |
| 3 | Errors & Failures | Difficulty in handling errors. | Yes | The algorithm needs to improve its error handling capabilities. |
| 4 | User Autonomy | Provides control to the user. | Yes | Users can control AI parameters like prompts and control net, allowing creative control over outcomes. |
| 5 | Accessibility | Designed for diverse users. | Needs Improvement | The design needs to be more inclusive and accessible for diverse user groups. |
| 6 | Workflow integration | Seamless integration into existing workflows. | Needs Improvement | The user experience needs refining to ensure seamless integration with existing design processes. |
| 7 | Rendering Performance | Quality of Visualization. | Needs Improvement | The rendering process, while functional, needs improvements for consistency and reliability. |
| 8 | Creative Amplification | Expandable use case. | Yes | The algorithm shows potential in advancement with many more versions to come. |
Github Repo with the Code and Screenshot
calluxpore/AI-Enhanced-Real-time-Algorithm-for-Streamlined- Rendering-in-a-3D-Modeling-workflow-AIR-STREaM- (github.com)
Hi-res Image of algorithm
https://calluxpore.github.io/AI-Enhanced-Real-time-Algorithm- for-Streamlined-Rendering-in-a-3D-Modeling-workflow-AIR-STREaM-/Hi-Res%20Algorithm.png
{kind=link}
Presentation
https://pitch.com/embed-link/ir92zi
AI Tools Declaration
In this project, I worked with a bunch of AI models that were already trained to understand text, images, audio, and to create new images. I got these models/ UI from places like HuggingFace, Civitai, Automatic1111, Midjourney, Niji Journey, and Microsoft Designer. I made sure to use all the models the right way, following their licenses and rules. I also tried making some custom models of my own, especially in the first experiment where I was making custom GPTs. These custom models were trained with data that was either free for anyone to use or data that I owned. For example, I used the Stable Diffusion Web UI (Automatic 1111) to train a custom model with symbols from the movie “Arrival” that I found on a Github Repo. This model was just for testing and wasn’t shared with others; I deleted it after I made it because it didn’t work the way I hoped it would.
| Category | Platforms |
| Text | Chat GPT, Open AI API, Jan AI, LM Studio, VsCode, Perplexity, Copilot (Bing) |
| Image | Automatic 1111, Invoke, Comfy UI, Vlad Diffusion, Discord, Stability AI, Microsoft Designer, Adobe Firefly, Nvidia Omniverse, Foocus, Stable Matrix |
| Audio | Eleven Labs, Natural reader |
| Category | Platforms |
| Text | Open Ai API, Chat GPT, GPT 3.5/4, Mixtral 8*7B Instruct q4, Phi-2 3B q8, Github Copilot, Claude 2.1, Gemini Pro |
| Image | Stable Diffusion, Mid Journey, Niji Journey, Stability AI, Microsoft Designer, Adobe Firefly |
| Category | Platforms |
| Text | Obsidian, VsCode, Cursor, Webstorm, Zotero, Rhino/ Grasshopper |
| Image | Chainner, Grasshopper |
References
* LM Studio—Discover and run local LLMs. (n.d.). Retrieved January 29, 2024, from https:// lmstudio.ai
AI Photo Editor—Adobe Photoshop. (n.d.). Retrieved January 29, 2024, from https:// www.adobe.com/products/photoshop/ai.html
AI Voice Generator & Text to Speech | ElevenLabs. (n.d.). Retrieved January 29, 2024, from https://elevenlabs.io/
AI Voices—NaturalReader Home. (n.d.). Retrieved January 29, 2024, from https:// www.naturalreaders.com/
Ambrosinus Toolkit. (2022, October 19). [Text]. Food4Rhino. https://www.food4rhino.com/en/ app/ambrosinus-toolkit
Anime Pastel Dream—Soft—Baked vae | Stable Diffusion Checkpoint | Civitai. (2023, May 19). https://civitai.com/models/23521/anime-pastel-dream
AniMerge—V2.6 | Stable Diffusion Checkpoint | Civitai. (2024, January 9). https://civitai.com/ models/144249/animerge
AniVerse—V2.0 (HD) | Stable Diffusion Checkpoint | Civitai. (2024, January 16). https:// civitai.com/models/107842/aniverse
architecture_Exterior_SDlife_Chiasedamme—V4.0 Exterior | Stable Diffusion Checkpoint | Civitai. (2024, January 15). https://civitai.com/models/114612/ architectureexteriorsdlifechiasedamme
ArchitectureRealMix—V1repair | Stable Diffusion Checkpoint | Civitai. (2023, June 28). https:// civitai.com/models/84958/architecturerealmix
AUTOMATIC1111. (2022). Stable Diffusion Web UI [Python]. https://github.com/ AUTOMATIC1111/stable-diffusion-webui (Original work published 2022)
Bifocals. (2016, February 22). [Text]. Food4Rhino. https://www.food4rhino.com/en/app/bifocals chaiNNer-org/chaiNNer. (2024). [Python]. chaiNNer. https://github.com/chaiNNer-org/chaiNNer (Original work published 2021)
ChatGPT. (n.d.). Retrieved January 29, 2024, from https://openai.com/chatgpt
Claude 2. (n.d.). Retrieved January 29, 2024, from https://www.anthropic.com/news/claude-2 comfyanonymous. (2024). Comfyanonymous/ComfyUI [Python]. https://github.com/ comfyanonymous/ComfyUI (Original work published 2023)
Copilot. (n.d.). Retrieved January 29, 2024, from https://www.bing.com/copilot? toWww=1&redig=D2D0F5A1CFAA43FCBBDB85C6CCD45C85
Counterfeit-V3.0—V3.0 | Stable Diffusion Checkpoint | Civitai. (2023, October 24). https:// civitai.com/models/4468/counterfeit-v30
CUDA Toolkit—Free Tools and Training | NVIDIA Developer. (n.d.). Retrieved January 29, 2024, from https://developer.nvidia.com/cuda-toolkit
Cursor—The AI-first Code Editor. (n.d.). Retrieved January 29, 2024, from https://cursor.sh/ CyberRealistic—V4.1 “Back to Basics” | Stable Diffusion Checkpoint | Civitai. (2023, December 11). https://civitai.com/models/15003/cyberrealistic
Discord | Your Place to Talk and Hang Out. (n.d.). Retrieved January 29, 2024, from https:// discord.com/
DreamShaper—8 | Stable Diffusion Checkpoint | Civitai. (2024, January 3). https://civitai.com/ models/4384/dreamshaper
Envvi/Inkpunk-Diffusion · Hugging Face. (n.d.). Retrieved January 29, 2024, from https:// huggingface.co/Envvi/Inkpunk-Diffusion
Gemini—Google DeepMind. (n.d.). Retrieved January 29, 2024, from https://deepmind.google/ technologies/gemini/
Git. (n.d.). Retrieved January 29, 2024, from https://git-scm.com/
GitHub Copilot · Your AI pair programmer. (n.d.). GitHub. Retrieved January 29, 2024, from https://github.com/features/copilot? ef_id=_k_9851d333cd3d17412792b68ba71719d3_k_&OCID=AIDcmmofjgdhvp_SEM k_9851d3 33cd3d17412792b68ba71719d3_k_&msclkid=9851d333cd3d17412792b68ba71719d3
GitHub: Let’s build from here. (n.d.). GitHub. Retrieved January 29, 2024, from https:// github.com/
InvokeAI. (n.d.). GitHub. Retrieved January 29, 2024, from https://github.com/invoke-ai Ladybug Tools. (2016, October 8). [Text]. Food4Rhino. https://www.food4rhino.com/en/app/ ladybug-tools
Liu, V., Vermeulen, J., Fitzmaurice, G., & Matejka, J. (2023). 3DALL-E: Integrating Text-to-Image AI in 3D Design Workflows (arXiv:2210.11603). arXiv. https://doi.org/10.48550/arXiv.2210.11603 lllyasviel. (2024). Lllyasviel/Fooocus [Python]. https://github.com/lllyasviel/Fooocus (Original work published 2023)
LykosAI/StabilityMatrix. (2024). [C#]. Lykos AI. https://github.com/LykosAI/StabilityMatrix (Original work published 2023)
Lyriel—V1.6 | Stable Diffusion Checkpoint | Civitai. (2023, August 13). https://civitai.com/ models/22922/lyriel
MeinaPastel—V6 ( Pastel ) | Stable Diffusion Checkpoint | Civitai. (2023, July 2). https:// civitai.com/models/11866/meinapastel
Mickey mouse—V1.0 | Stable Diffusion LoRA | Civitai. (2023, November 29). https://civitai.com/ models/105071/mickey-mouse
Microsoft Designer—Stunning designs in a flash. (n.d.). Retrieved January 29, 2024, from https:// designer.microsoft.com
Midjourney. (n.d.). Midjourney. Retrieved January 29, 2024, from https://www.midjourney.com/ home?callbackUrl=%2Fexplore
Moonlight | Food4Rhino. (n.d.). Retrieved January 29, 2024, from https://www.food4rhino.com/ en/app/moonlight
MoonMix—V1.8 | Stable Diffusion Checkpoint | Civitai. (2023, March 13). https://civitai.com/ models/19129/moonmix
Network, S. D. created this N. (n.d.). Grasshopper. Retrieved January 29, 2024, from https:// www.grasshopper3d.com/
Niji・journey. (n.d.). Niji・journey. Retrieved January 29, 2024, from https://nijijourney.com/en/
Novel Inkpunk F222—V1 | Stable Diffusion Checkpoint | Civitai. (2022, December 23). https:// civitai.com/models/1186/novel-inkpunk-f222
NVIDIA Omniverse. (n.d.). NVIDIA. Retrieved January 29, 2024, from https://www.nvidia.com/en- us/omniverse/
Obsidian—Sharpen your thinking. (n.d.). Retrieved January 29, 2024, from https://obsidian.md/
OpenAI API. (n.d.). Retrieved January 29, 2024, from https://openai.com/blog/openai-api Open-source ChatGPT Alternative | Jan. (n.d.). Retrieved January 29, 2024, from https://jan.ai/ PerfectDeliberate—V4.0 Review | Civitai. (n.d.). Retrieved January 29, 2024, from https:// civitai.com/posts/263839
Perplexity. (n.d.). Retrieved January 29, 2024, from https://www.perplexity.ai/
Product Design (minimalism-eddiemauro)—Eddiemauro 2.0 | Stable Diffusion Checkpoint | Civitai. (2023, June 14). https://civitai.com/models/23893/product-design-minimalism- eddiemauro
Protogen v2.2 (Anime) Official Release—Protogen v2.2 | Stable Diffusion Checkpoint | Civitai. (2023, March 27). https://civitai.com/models/3627/protogen-v22-anime-official-release Protogen x3.4 (Photorealism) Official Release—Protogen x3.4 | Stable Diffusion Checkpoint | Civitai. (2023, August 18). https://civitai.com/models/3666/protogen-x34-photorealism-official- release
Protogen x5.3 (Photorealism) Official Release—Protogen x5.3 | Stable Diffusion Checkpoint | Civitai. (2023, March 14). https://civitai.com/models/3816/protogen-x53-photorealism-official- release
RealCartoon3D – V13 | Stable Diffusion Checkpoint | Civitai. (2023, December 31). https:// civitai.com/models/94809/realcartoon3d
Realistic Vision V6.0 B1—V5.1 (VAE) | Stable Diffusion Checkpoint | Civitai. (2024, January 21). https://civitai.com/models/4201/realistic-vision-v60-b1
ReV Animated—V1.2.2-EOL | Stable Diffusion Checkpoint | Civitai. (2023, November 30). https://civitai.com/models/7371/rev-animated
Rhino—Rhinoceros 3D. (n.d.). Retrieved January 29, 2024, from https://www.rhino3d.com/ Runwayml/stable-diffusion-v1-5 · Hugging Face. (n.d.). Retrieved January 29, 2024, from https:// huggingface.co/runwayml/stable-diffusion-v1-5
Stability AI. (n.d.). Stability AI. Retrieved January 29, 2024, from https://stability.ai SynthwavePunk—V2 | Stable Diffusion Checkpoint | Civitai. (2023, June 12). https://civitai.com/ models/1102/synthwavepunk
The Stable Diffusion Guide �. (n.d.). Retrieved January 29, 2024, from https://huggingface.co/ docs/diffusers/v0.14.0/en/stable_diffusion
TheBloke/Mixtral-8x7B-v0.1-GGUF · Hugging Face. (n.d.). Retrieved January 29, 2024, from https://huggingface.co/TheBloke/Mixtral-8x7B-v0.1-GGUF
TheBloke/phi-2-GGUF · Hugging Face. (n.d.). Retrieved January 29, 2024, from https:// huggingface.co/TheBloke/phi-2-GGUF
ToonYou—Beta 6 . | Stable Diffusion Checkpoint | Civitai. (2023, September 4). https:// civitai.com/models/30240/toonyou
Visual Studio Code—Code Editing. Redefined. (n.d.). Retrieved January 29, 2024, from https:// code.visualstudio.com/
Vlado Mandic, V. (2022). SD.Next [Python]. https://github.com/vladmandic/automatic (Original work published 2022)
WebStorm: The JavaScript and TypeScript IDE, by JetBrains. (n.d.). JetBrains. Retrieved January 29, 2024, from https://www.jetbrains.com/webstorm/
Welcome to Python.org. (n.d.). Retrieved January 29, 2024, from https://www.python.org/
WolframResearch/Arrival-Movie-Live-Coding. (2024). [Mathematica]. Wolfram Research, Inc. https://github.com/WolframResearch/Arrival-Movie-Live-Coding (Original work published 2017) XpucT (Khachatur). (2024, January 8). https://huggingface.co/XpucT
Yoo, S., Lee, S., Kim, S., Hwang, K. H., Park, J. H., & Kang, N. (2021). Integrating deep learning into CAD/CAE system: Generative design and evaluation of 3D conceptual wheel. Structural and Multidisciplinary Optimization, 64(4), 2725–2747. https://doi.org/10.1007/s00158-021-02953-9 Zotero | Your personal research assistant. (n.d.). Retrieved January 29, 2024, from https:// www.zotero.org/
Leave a Reply